Accelerating the future of perception features research
The Spatial Meshing feature enriches the way users interact with the 3D environment and provides better augmented reality experiences. As example, Spatial Meshing allows users to place virtual board games on top of a table and to drive virtual avatars to navigate through the environment. One of the vital ingredients for a good user experience when using Spatial Meshing is accurate and efficient 3D reconstruction. In this post, we briefly cover two of our recent public contributions to improve depth perception and 3D reconstructions, accepted for presentation in the International Conference on Computer Vision (ICCV).
September 29, 2023

Depth-Guided Neural 3D Scene Reconstruction
Without depth sensors, existing volumetric neural scene reconstruction methods (Atlasi, NeuralReconii, etc.) suffer from depth ambiguity when back projecting 2D features to 3D space. In this work, we propose to utilize depth priors, obtained from efficient monocular depth estimation, to guide the feature back-projection process. Figure 1 illustrates how depth guidance could reduce erroneous features and improve separation of objects in the reconstruction.
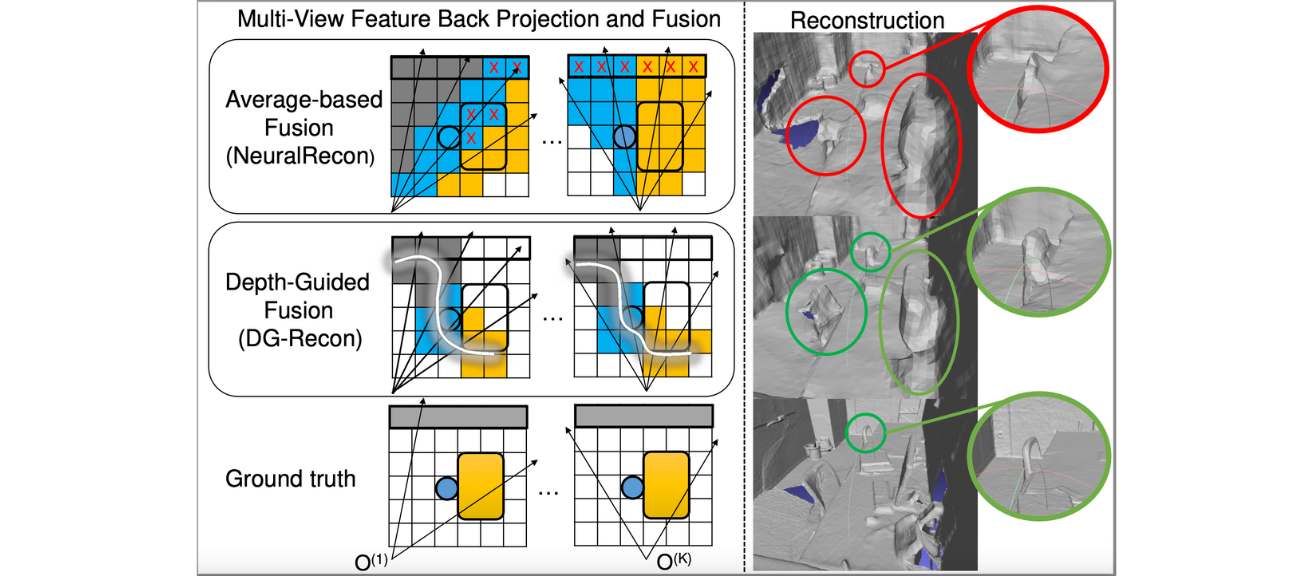
Figure 1. Feature back-projection without (Average-based) and with depth guidance.
Another common pitfall of volumetric-based scene reconstruction methods is the use of average for multi-view feature fusion. The average operation discards the cross-view consensus information which is critical to distinguish voxels on and off surfaces. We propose two alternative fusion mechanisms: the variance-based (var) fusion and the cross-attention-based (c-att) fusion. The non-learnable variance operator is shown to be as efficient as the average operator and delivers significantly better reconstruction. The learnable cross-attention module further improves the reconstructed geometry while being more efficient than the existing self-attention-based fusion modules.
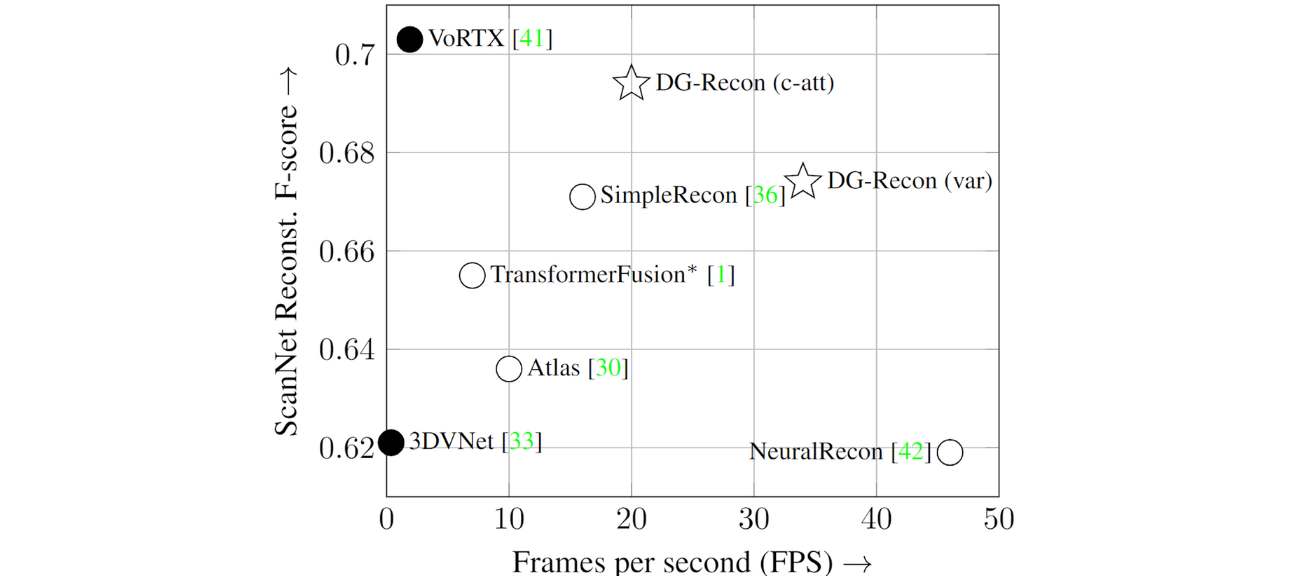
Figure 2. The accuracy-efficiency tradeoff for 3D reconstruction. Closed circles: offline methods; Open circles and stars: online methods.
Figure 2 compares the two variants of our method (DG-Recon) against the SOTA 3D reconstruction methods, including VoRTXiii, SimpleReconiv , TransformerFusionv and 3DVNetvi, in terms of the reconstruction F-score and frames per second. Our method achieves the best performance-efficiency trade-off among online methods and reaches F-score close to the SOTA offline method, VoRTX. The video below demonstrates a live reconstruction session with our method. The geometry inside the office room is incrementally updated and refined every 9 keyframes (approximately every 1.5 seconds).
Figure 3. Live reconstruction with DG-Recon.
For more technical details on this work, please refer to our ICCV23 paper: Jihong Ju, Ching Wei Tseng, Oleksandr Bailo, Georgi Dikov, and Mohsen Ghafoorian, “DG-Recon: Depth-Guided Neural 3D Scene Reconstruction”, International Conference on Computer Vision 2023.
Improved Self-supervised Depth Estimation on Reflective Surfaces
Requiring per-pixel ground-truth at large volume for getting a reliable supervised training is a laborious task that also depends on specialized hardware, e.g., LIDAR that limits the size and diversity of the data. Therefore, self-supervised training schemes have gained extensive attention, resulting in competitive self-supervised methods that mainly rely on photometric image reconstruction lossviii. However, the discrepancy between the optimization objective (photometric image reconstruction) and the actual test-time use (dense depth prediction) can sometimes result in degenerate solutions that satisfy the training objective but are not desirable from the the point of view of actual usage. One such example in this scenario is the behavior of self-supervised depth models on specular/reflective surfaces, where the models are observed to predict much larger depth values than the real surface distance on the specular reflections. Figure 4 depicts the reason why this happens, an example demonstrating such mis-predictions and how 3DDistillation (3DD), our proposed method published at ICCV23, resolves this issue.
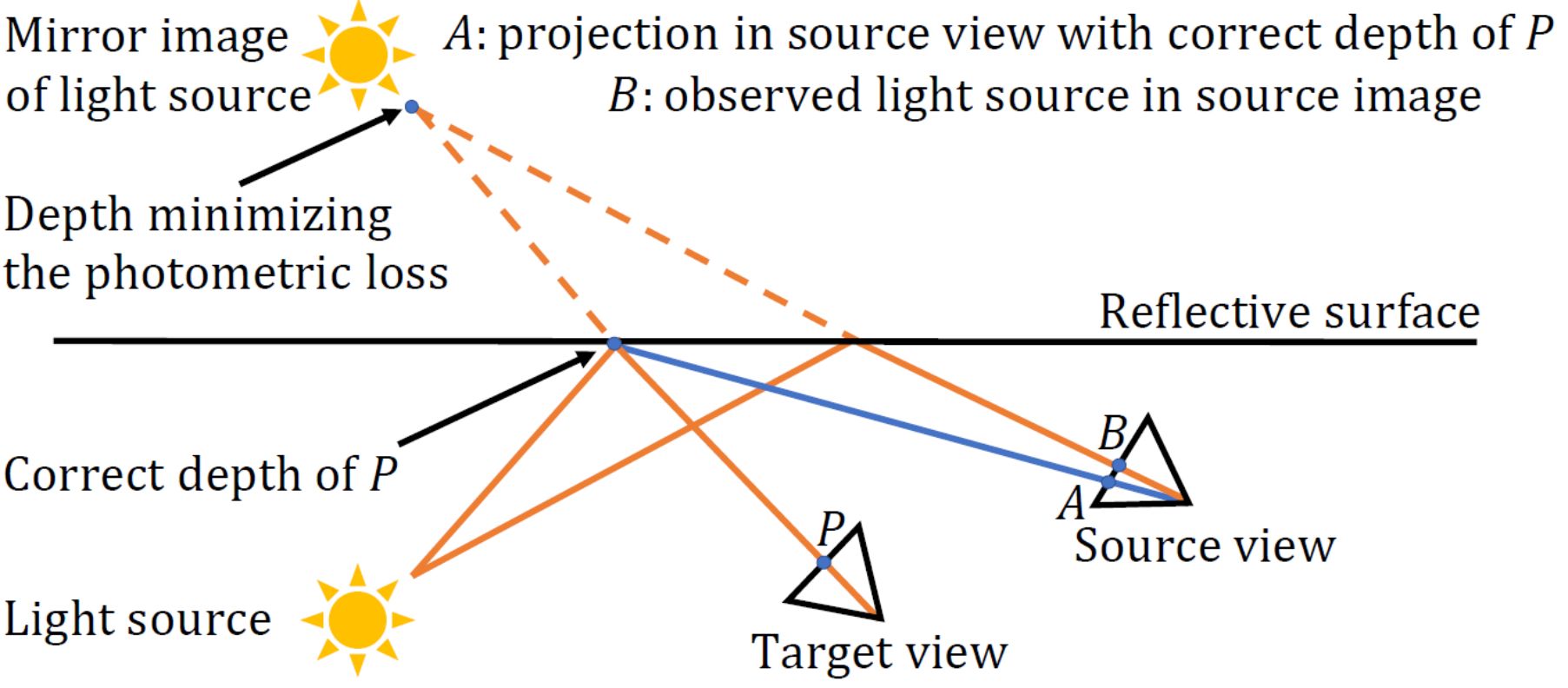
Figure 4. An illustration of the reason for mis-prediction of self-supervised depth models on specular surfaces.
The main idea behind our proposed method is to bring further 3D prior in the training process through the 3D fusion of the predicted depth, projecting them back to the corresponding frames and using them as pseudo-labels to train the model; thus the name “3DDistillation”! As shown in quantitative and qualitative analysis (see Figures 5 and 6), this significantly rectifies the model’s behavior on the specular surfaces, while keeping the model still fully self-supervised with no requirement to sensory ground-truth. By experimenting with different model architectures (Monodepth2, HR-Depthix, MonoVITx ), we showed that our contributions are generic and agnostic to the underlying architecture.
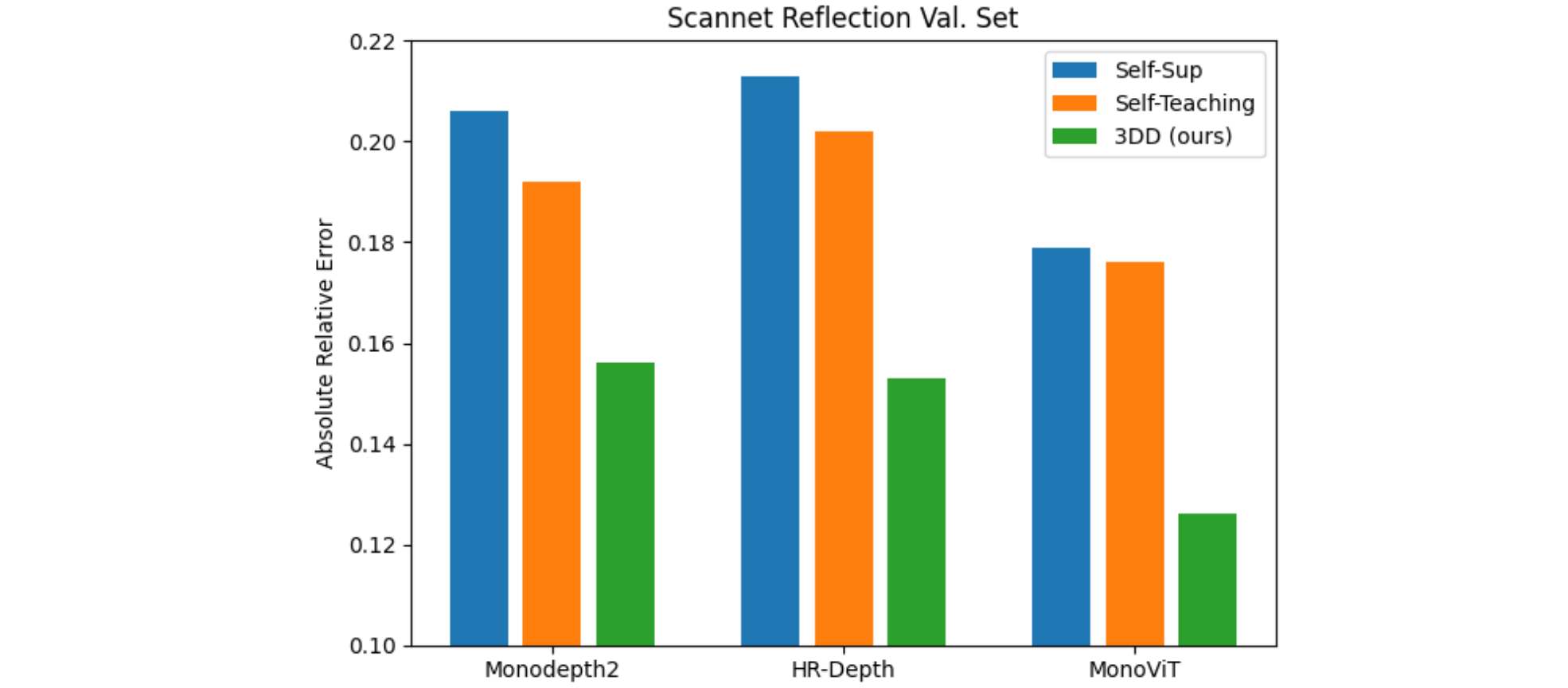
Figure 5. Quantitative comparisons on Scannet Reflection Set with various backbone models.

Figure 6. Sample qualitative depth predictions and 3D reconstruction from 3D Distillation.
For more technical details on this work, please refer to our ICCV23 paper: Xuepeng Shi, Georgi Dikov, Gerhard Reitmayr, Tae-Kyun Kim, and Mohsen Ghafoorian, “3D Distillation: Improving Self-Supervised Monocular Depth Estimation on Reflective Surfaces”, International Conference on Computer Vision 2023.
Find out more about Spatial Meshing and its use cases.
The aforementioned contributions are just two examples of the many cutting-edge research projects we are conducting at XR Labs Europe. Our goal is to constantly push the boundaries of the perception feature’s quality that are offered through the Snapdragon Spaces XR Developer Platform. The team actively explores novel ideas and methodologies to further improve our methods and their accuracy and efficiency, and to enable a better experience for our XR technology end-users and developers.
i Murez, Zak, et al. “Atlas: End-to-end 3d scene reconstruction from posed images.” European Conference on Computer Vision 2020.
iiSun, Jiaming, et al. “NeuralRecon: Real-time coherent 3D reconstruction from monocular video.” Conference on Computer Vision and Pattern Recognition. 2021.
iiiStier, Noah, et al. “Vortx: Volumetric 3d reconstruction with transformers for voxelwise view selection and fusion.” International Conference on 3D Vision. 2021.
ivSayed, Mohamed, et al. “SimpleRecon: 3D reconstruction without 3D convolutions.” European Conference on Computer Vision. 2022.
vBozic, Aljaz, et al. “Transformerfusion: Monocular rgb scene reconstruction using transformers.” Advances in Neural Information Processing Systems. 2021
viRich, Alexander, et al. “3dvnet: Multi-view depth prediction and volumetric refinement.” International Conference on 3D Vision. 2021.
viiGodard, Clément et al., “Unsupervised monocular depth estimation with left-right consistency.” Conference on Computer Vision and Pattern Recognition. 2017.
viiiGodard, Clément, et al. “Digging into self-supervised monocular depth estimation.” International Conference on Computer Vision. 2019.
ixDai, Angela, et al. “ScanNet: Richly-annotated 3d reconstructions of indoor scenes.” Conference on Computer Vision and Pattern Recognition. 2017.
xLyu, Xiaoyang, et al. “Hr-depth: High resolution self-supervised monocular depth estimation.” AAAI Conference on Artificial Intelligence. 2021.
xiZhao, Chaoqiang, et al. “Monovit: Self-supervised monocular depth estimation with a vision transformer.” International Conference on 3D Vision. 2022.
Snapdragon branded products are products of Qualcomm Technologies, Inc. and/or its subsidiaries.